最近在了解一些安卓隐私合规工作,主要想了解工作是如何基于 NLP 进行隐私政策文本处理的,因此记录一下经典之作 PolicyLint 的原理
概述
本文是发表于 Sec19 的PolicyLint: Investigating Internal Privacy Policy Contradictions on Google Play
这篇文章具体研究问题是,隐私政策文本内的一些表述矛盾,如同时在隐私政策内声明 我们不会收集您的个人信息 及 我们将收集您的手机号用于xxx ,这种情况被作者认为是隐私政策内部矛盾。
Challenge
对信息的引用以不同的语义层次表达
- 先前工作的术语假定关系需要指定,缺乏全面性及可扩展性
- 没有捕获推理隐私政策中提到的数据类型和实体所需的所有特定关系
隐私政策包括负面分享和收集声明
- 先前工作忽略负面声明
- 粒度粗无法处理复杂的陈述
Insight
句子结构 informs 语义
共享和收集语句通常遵循一组可学习的模板。PolicyLint 使用这些模板从这些语句中提取一个四元组:(参与者、动作、数据对象、实体)。例如,我们 [Actor] 与广告商 [entity] 共享 [action] 个人信息 [data object]。
句子结构还可以更深入地了解更复杂的负面共享。例如,“我们与广告商共享您的电子邮件地址以外的个人信息。”
PolicyLint 通过建立在现有的词性和依赖解析器之上,从隐私政策语句中提取此类语义。隐私政策编码本体
由于隐私政策的法律性质,一般术语通常根据示例或其组成部分来定义。虽然可能不会为政策中使用的所有术语定义语义关系,但这些关系应该存在于我们数据集中的其他一些政策中。通过处理大量隐私政策,PolicyLint 自动生成特定于政策的本体(一个用于数据对象,一个用于实体)。PolicyLint 使用赫斯特模式 [16] 提取术语定义,我们已经将其扩展到我们的领域。
Design
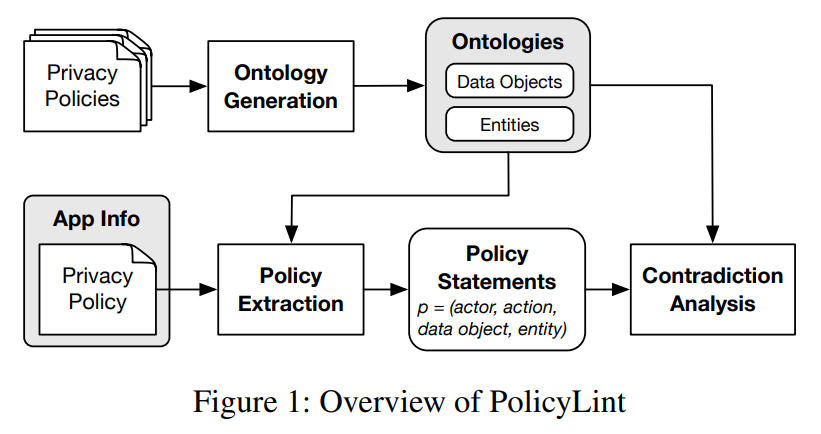
- Ontology Generation
目标:在隐私政策中定义术语之间的推定(“is-a”)关系,以允许对不同粒度的语言进行推理Example 1. We may share demographic information, such as your age and gender, with advertisers.
PolicyLint 使用这样的句子来自动发现大量隐私策略中的推定关系。 它侧重于数据对象和接收数据的实体。
PolicyLint 使用半自动化和数据驱动的技术来生成本体。它将本体生成分为三个主要部分。
NER domain adaption
PolicyLint 对现有的基于统计的命名实体识别 (NER) 模型进行 domain 适应。NER 用于标记句子中的数据对象和实体,不仅捕获术语,还捕获句子中的上下文。
为了识别数据对象及实体之间的假定关系,PL 需要识别词元代表的数据对象或实体。例如上面的例子,[demographic information, age, gender] 会被识别为数据对象,[we, advertisers] 会被识别为实体。
NER(named-entity recognition):基于统计的一种技术,用于标记句子中的数据对象及实体。
Subsumptive Relationship Extraction
PolicyLint 通过使用一组 11(??在后续给出的表中只有九种,文章在这一节的开头似乎写错了) 种具有强制命名实体标签约束的词汇句法模式来学习标记数据对象和实体的假定关系。
PolicyLint 使用一组 9 种词汇句法模式来发现句子中的推定关系
对每组 data object 和 entity。PolicyLint 通过对文本进行词形还原并用它们的同义词替换术语来规范化关系。
同义词识别
人工做的。按照 data object 出现的频率输出,频率最高的词,如果其他 data object 包含他,这些 data object 一律标注。然后结合领域知识,将同义不同词的单词也标记。
1 | 如,发现 location 这个词出现频率最高,那么其余任意包含 location 的词,输出,人工阅读,并将他们统一标记为 geographic location。 |
Ontology Construction
PolicyLint 将一组种子词作为输入,并使用在上一步中发现的假定关系生成数据对象/实体本体。 它迭代地将关系添加到本体,直到达到一个固定点。
一组 seed,找 seed 相关的 relationships,在这些 relationships 中继续找是否有其他表述的 data object,继续找这些 data object 相关的 relationships,直到没有新的。
- Policy Statement Extraction
将一条 policy statement 表示为 (actor, action, data object, entitiy)1
如,we will share your personal information with advertisers --> (we, share, personal information, advertisers)
DED(Data and Entity Dependency) Tree Construction
PolicyLint 合并名词短语并迭代句子标记以标记 SoC 动词。确保词元的词性(part-of-speech)标签是动词并且动词的引理在 PolicyLint 的手动管理的术语列表中
PolicyLint 然后提取句子的基于依存关系的解析树,其节点用数据对象、实体和 SoC 动词标签进行标记。
DED 树会删除与数据对象、实体或 SoC 动词无关的节点和路径,并执行一组简化以概括表示。
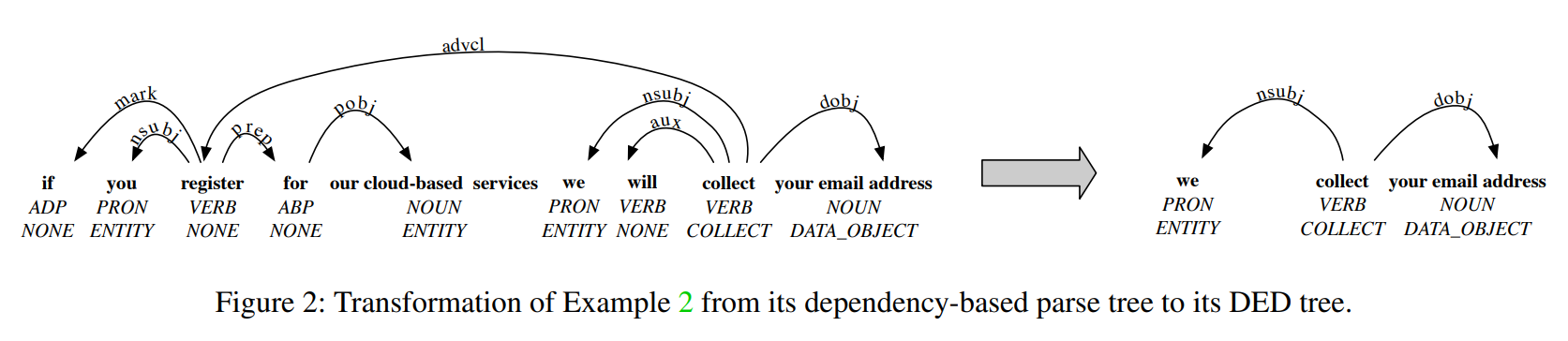
- 负面表达 :PolicyLint 通过检查基于依赖的分析树中的否定修饰符来识别否定动词。如果动词被否定,PolicyLint 将节点标记为负面情绪。 PolicyLint 在三种情况下将负面情绪传播到后代动词节点。
- 如果后代动词是带有否定动词的连词动词短语的一部分,则会传播负面情绪。 “We do not sell, rent, or trade your personal information,” means “not sell,” “not rent,” and “not trade.”
- 如果后裔动词对否定动词有一个开放式从句补语,就会传播负面情绪。“We do not require you to disclose any personal information,” initially has “require” marked with negative sentiment. Since “disclose” is an open clausal complement to “require,” it is marked with negative sentiment.
- 如果后代动词是否定动词的状语从句修饰语,则会传播负面情绪。 例如,“我们不会收集您的信息以与广告商分享”,最初的“收集”标记为负面情绪。 由于“share”是“collect”的状语从句修饰语,“share”被标记为负面情绪。
- 例外表述 :含如 except、unless、aside、apart from、besides、without、not including 这类表例外情况的句子。
- 对于每个已识别的异常子句,PolicyLint 从异常子句向下遍历分析树,以识别与该异常相关的动词短语(主语-动词-宾语)和名词短语。
- PolicyLint 然后从异常项向上遍历以识别最近的动词节点,并将在向下遍历中识别的名词短语和动词短语列表附加为节点属性。
- 在某些情况下,该术语可能没有子树。例如,例外项可能是引入从句的标记。在“我们不会共享您的个人信息,除非得到同意”这句话中,除非”一词是引入从句“您的同意已获得”的标记。 对于空子树,PolicyLint 尝试从其父节点向下遍历。
SoC(sharing or collection) Sentence Identification
PolicyLint 遍历每个句子。如果句子包含至少一个 SoC 动词和数据对象(由 NER 标记),则 构建 DED 树,将句子的 DED 树与每个已知模式的 DED 树进行比较。
(1)句子的 DED 树的标签类型等同于已知模式的 DED 树的标签类型(例如,{entity, SoC_verb, data})
(2)已知模式的 DED 树是句子的 DED 树的子树